在当今数据驱动的时代,处理海量数据已成为企业的核心竞争力之一。Hadoop,作为大数据领域的基石,其重要性与日俱增。本文将从资深架构师的视角,为您系统性地剖析Hadoop的核心技术栈与服务生态,助您快速构建全局认知。
一、Hadoop的基石:核心组件深度解读
Hadoop并非单一软件,而是一个由多个关键组件构成的生态系统,其核心在于分布式存储与分布式计算。
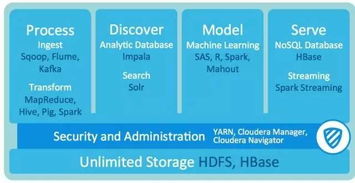
1. HDFS:数据的可靠仓库
Hadoop分布式文件系统(HDFS)是整个体系的存储基石。它采用主从架构:
- NameNode:作为“管理员”,负责管理文件系统的命名空间(如目录树、文件元数据)和客户端对文件的访问。它是集群的单一故障点,因此高可用方案至关重要。
- DataNode:作为“仓库管理员”,负责存储实际的数据块,并定期向NameNode报告其存储的块列表。数据默认会冗余存储三份,分布在不同机架上,确保了数据的可靠性与高可用。
2. MapReduce:经典的计算引擎
这是Hadoop最初的并行计算编程模型。其思想是“分而治之”:将一个大任务拆分为多个小任务(Map阶段),在集群中并行处理,再将结果汇总(Reduce阶段)。虽然如今更多被更高效的计算框架替代,但理解其“移动计算而非移动数据”的设计哲学,对掌握分布式计算精髓至关重要。
3. YARN:集群的资源管家
随着生态发展,Hadoop 2.0引入了YARN(Yet Another Resource Negotiator),它将资源管理与作业调度/监控功能分离。YARN由一个ResourceManager和多个NodeManager组成,负责统一管理集群的计算资源(CPU、内存),并为上层应用(如MapReduce、Spark、Flink)提供资源调度服务。这使得Hadoop从一个单一的计算系统演变为一个多应用的数据操作系统。
二、Hadoop的利器:关键技术服务与生态
单纯的核心组件不足以解决所有问题,围绕其形成的丰富生态才是Hadoop强大的真正体现。
* 数据仓库工具:Hive
对于熟悉SQL的分析师而言,直接编写MapReduce程序门槛过高。Hive应运而生,它提供了类SQL的查询语言(HQL),可将查询自动转换为MapReduce、Tez或Spark作业,极大地降低了大数据查询的门槛,是构建企业数据仓库(EDW)的常用选择。
* NoSQL数据库:HBase
当需要实时随机读写海量数据时,HDFS的顺序访问模型不再适用。HBase是一个构建在HDFS之上的分布式、面向列的NoSQL数据库。它能提供毫秒级的低延迟访问,适用于实时查询、增量数据更新等场景,是Hadoop生态中实现在线业务的关键。
- 数据采集与传输:Flume, Sqoop
- Flume:一个高可用的分布式海量日志采集、聚合和传输系统,擅长从各种数据源(如Web服务器日志)实时流入HDFS或Kafka。
- Sqoop:用于在Hadoop与结构化数据库(如MySQL, Oracle)之间高效传输批量数据的工具,是传统数据仓库与大数据平台之间的桥梁。
* 工作流调度:Oozie
在大数据平台中,数据处理任务往往复杂且相互依赖。Oozie是一个工作流调度引擎,可以管理和协调多个Hadoop作业(如MapReduce, Hive, Pig, Sqoop)按照特定的时间或依赖关系有序执行,实现流程自动化。
三、架构师的实战视角:技术选型与规划建议
- 明确场景,选择组件:
- 离线批处理与分析:首选 Hive + Spark(计算引擎)。Spark因其内存计算、DAG执行引擎,性能远超MapReduce。
- 实时计算与流处理:考虑 Spark Streaming 或 Flink,它们可与HDFS、Kafka等无缝集成。
- 实时交互查询:可选用 Impala 或 Presto,它们提供低延迟的SQL查询能力。
- 海量数据随机访问:HBase 是不二之选。
- 集群规划与高可用:
- 规模预估:根据数据量、计算复杂度、增长预期规划节点数量(通常区分Master节点和Worker/Slave节点)。
- 高可用部署:务必为NameNode和ResourceManager部署HA方案,避免单点故障导致集群不可用。
- 资源隔离:利用YARN的队列管理,为不同业务部门或任务类型划分资源池,保证关键任务资源,提升集群整体利用率。
3. 未来趋势与云原生:
传统自建Hadoop集群运维复杂。当前趋势是拥抱云原生和存算分离。例如,将数据存储在 对象存储(如AWS S3, 阿里云OSS) 上,计算集群按需弹性扩缩容,或者直接采用云厂商提供的 E-MapReduce 等托管服务,以降低运维成本,聚焦业务价值。
****
理解Hadoop,关键在于掌握其“分布式存储”与“资源统一调度”两大核心思想。整个生态系统都是围绕如何更高效、更便捷地在这两个基础上存储和处理数据而展开。作为架构师,不应局限于某一组件,而应通盘考虑业务需求、技术特性、团队能力和运维成本,在Hadoop丰富的技术图谱中选择最合适的组合,构建稳定、高效、面向未来的大数据平台。从HDFS/YARN的基石,到Hive/HBase等上层应用,再到云原生的演进,这条技术脉络清晰可见,掌握它,您就握住了开启大数据殿堂的钥匙。